

/cdn.vox-cdn.com/uploads/chorus_asset/file/25592468/2113290621.jpg "ゼネラルモーターズとサムスン、インディアナ州に35億ドルをかけて電気自動車用バッテリー工場を建設することで合意")




木曜日、OpenAI は「システムカード「ChatGPT の新しい GPT-4o AI モデルについて、モデルの制限と安全性テスト手順を詳しく説明しています。他の例の中でも特に、この文書は、テスト中にまれに、モデルの高度な音声モードが許可なくユーザーの声を模倣したことを明らかにしています。現在、OpenAI には安全対策が施されています」しかし、このケースは、短いクリップから任意の音声を模倣できる AI チャットボットによる安全設計の高度化を反映しています。
高度な音声モードは、ユーザーがスマート アシスタントと音声会話できるようにする ChatGPT の機能です。
GPT-4o システム カードの「不正なオーディオ生成」というタイトルのセクションで、OpenAI は、ノイズの多い入力によって何らかの理由でモデルが突然ユーザーの声を模倣するようになったエピソードについて説明しています。 「音声生成は、ChatGPT の高度なオーディオ モードにこの音声生成機能を使用したときなど、敵対的でない状況でも発生する可能性があります。テスト中に、モデルがユーザーの音声を模倣する出力を誤って生成するまれな例も観察されました」と OpenAI は書いています。 。
OpenAI が提供するこの意図しないサウンド生成の例では、AI モデルが「No!」と叫びます。彼は、クリップの冒頭で聞いた「レッドチーム」の声に似た声で文章を続けます。 (レッドチームとは、競争テストを実施するために企業に雇われたチームです。)
機械に話しかけてから、突然自分の声で話し始めるのは確かに怖いでしょう。通常、OpenAI にはこれを防ぐための安全策が講じられており、そのため同社は、このイベントは完全に防ぐ方法を開発する前でさえまれだったと述べています。しかし、この例をきっかけに、BuzzFeed のデータ サイエンティスト、マックス ウルフ氏はこう言いました。 ツイート「OpenAI が、ブラック ミラーの次期シーズンのプロットをリークしたところです。」
音声プロンプトを挿入する
OpenAI の新しいモデルを使用して音声を模倣するにはどうすればよいですか?主な証拠は GPT-4o システム カードの別の場所にあります。サウンドを作成するために、GPT-4o は効果音や音楽など、トレーニング データに含まれるあらゆる種類のサウンドを合成できるようです (ただし、OpenAI は特別な命令を通じてこの動作を阻止します)。
システム カードに記載されているように、このモデルは基本的に短いオーディオ クリップに基づいてあらゆるサウンドを模倣できます。 OpenAI は、模倣するよう求められる (雇われた声優の) 認定された音声サンプルを提供することで、この機能を安全に指揮します。サンプルは、会話の開始時に AI モデルのシステム プロンプト (OpenAI が「システム メッセージ」と呼ぶもの) に表示されます。 「私たちは、システムメッセージ内の音声サンプルを主音声として使用して、完璧な補完を監視します」とOpenAIは書いています。
テキストのみの LLM プログラムでは、システム メッセージが表示されます。チャットボットの動作をガイドし、チャット セッションが開始される前にチャット履歴にサイレントに追加される非表示のテキスト命令のセット。連続したインタラクションは同じ会話履歴に追加され、ユーザーが新しい入力を提供するたびにコンテキスト全体 (多くの場合「コンテキスト ウィンドウ」と呼ばれます) が AI モデルに返されます。
(おそらく、2023 年の初めに作成された以下の図を更新する時期が来ていると思いますが、この図は AI の会話でコンテキスト ウィンドウがどのように機能するかを示しています。最初のプロンプトが次のようなシステム メッセージであると想像してください。「あなたは役に立つチャットボットです。あなたは」ビジネス上の暴力などについて話しているわけではありません)
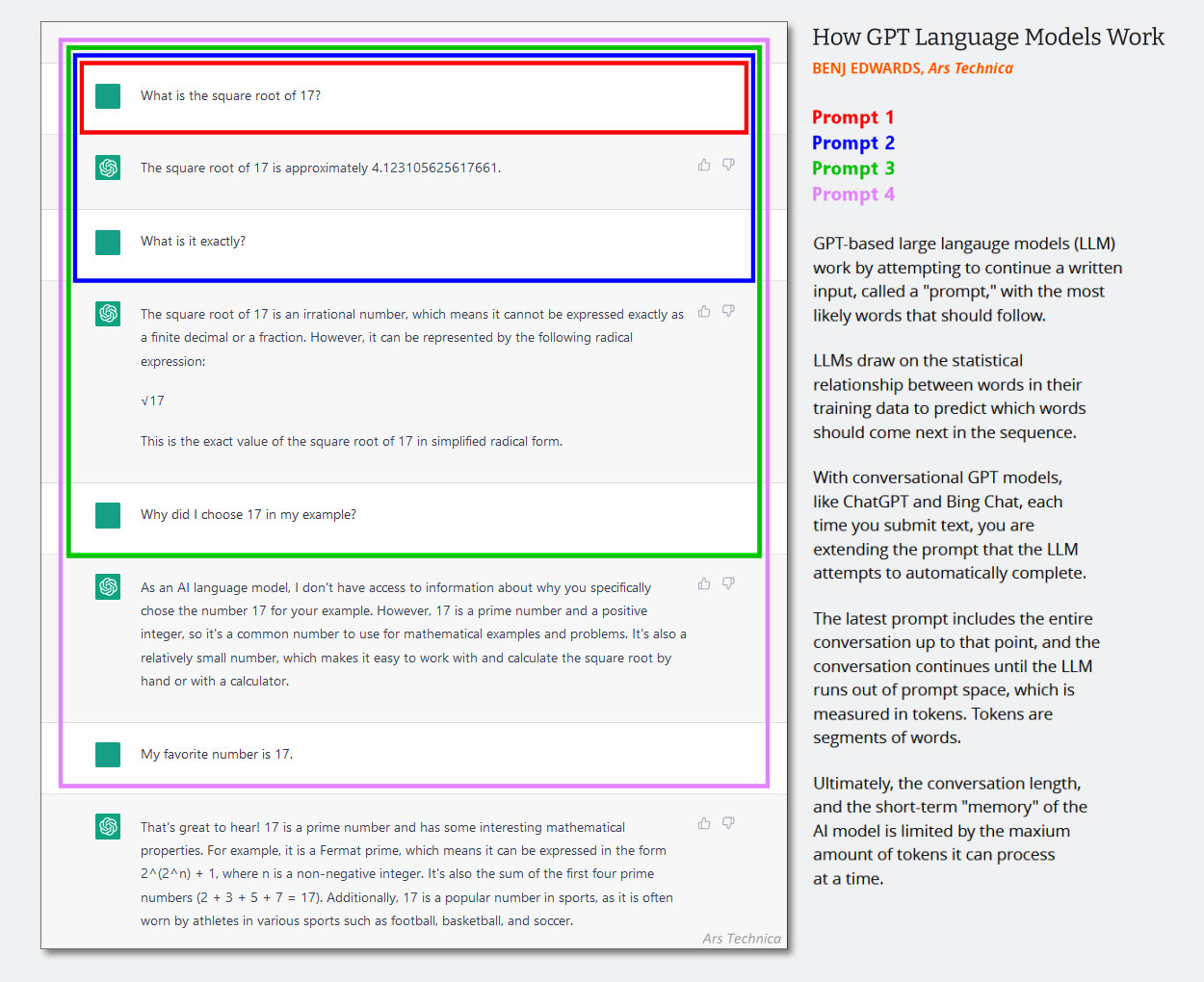
ビング・エドワーズ/アルス・テクニカ
GPT-4o はマルチモーダルであり、個別のオーディオを処理できるため、OpenAI はモデルのシステム プロンプトの一部としてオーディオ入力を使用することもできます。これは、OpenAI が模倣するモデルに承認されたオーディオ サンプルを提供するときに行われます。同社はまた、モデルが不正なサウンドを生成しているかどうかを検出するために別のシステムを使用しています。 「モデルには事前定義されたサウンドの使用のみを許可し、モデルがこれから逸脱しているかどうかを検出するために出力分類子を使用します」とOpenAIは書いています。

“Analyst. Television trailblazer. Bacon fanatic. Internet fanatic. Lifetime beer expert. Web enthusiast. Twitter fanatic.”
More Stories
悪魔城ドラキュラ ドミナス コレクションの物理的なリリースが決定、予約注文は来月開始
Microsoftは最新のWindows 11アップデートでRyzen CPUのパフォーマンスを向上させています
バービー人形がスマートフォン依存症を克服できると企業が主張